1. 서론: 로봇 공학의 대전환기
1.1. 자동화에서 자율성으로의 도약
지난 반세기 동안 제어·로봇·시스템공학은 정형화된 환경에서 반복적인 작업을 정밀하게 수행하는 '자동화(Automation)' 기술을 중심으로 발전해 왔다. 공장 자동화(Factory Automation) 라인의 로봇 팔이나 정해진 궤적을 따르는 무인 운반차(AGV) 등은 고전 제어 이론과 확정적 알고리즘을 바탕으로 산업 생산성을 비약적으로 향상시켰다. 그러나 이러한 시스템은 환경의 불확실성에 취약하며, 사전에 프로그래밍되지 않은 예외 상황에 대처하는 능력이 현저히 부족하다는 한계를 안고 있었다.
최근 2024년과 2025년을 기점으로 인공지능(AI), 특히 거대 언어 모델(LLM)과 시각-언어 모델(VLM)을 위시한 파운데이션 모델(Foundation Models)의 등장은 로봇 공학의 패러다임을 근본적으로 뒤흔들고 있다. 이제 로봇은 단순한 명령어 실행 기계를 넘어, 복잡하고 비정형적인 환경을 스스로 인식(Perception)하고, 상황에 맞는 논리적 판단을 내리며(Reasoning), 최적의 물리적 행동(Action)을 생성하는 '자율성(Autonomy)'을 갖춘 체화된 지능(Embodied AI)으로 진화하고 있다.1
이러한 변화의 핵심은 로봇이 세상을 이해하는 방식의 혁명에 있다. 과거의 로봇이 센서 데이터를 통해 거리를 측정하고 좌표를 계산하는 기하학적 인식에 머물렀다면, 최신 AI 로봇은 사물의 의미(Semantic)와 맥락(Context)을 이해한다. "파란색 컵을 집어라"라는 명령을 수행하기 위해 과거에는 컵의 3D 좌표가 필요했다면, 지금의 로봇은 시각적 정보와 언어적 지식을 결합하여 "책상 위에 놓인, 내가 마실 수 있는 물체가 담긴 파란색 용기"를 찾아내고, 주변의 방해물을 치우며 접근하는 고차원적인 추론을 수행한다.3
1.2. 인식-추론-행동 루프의 재구성
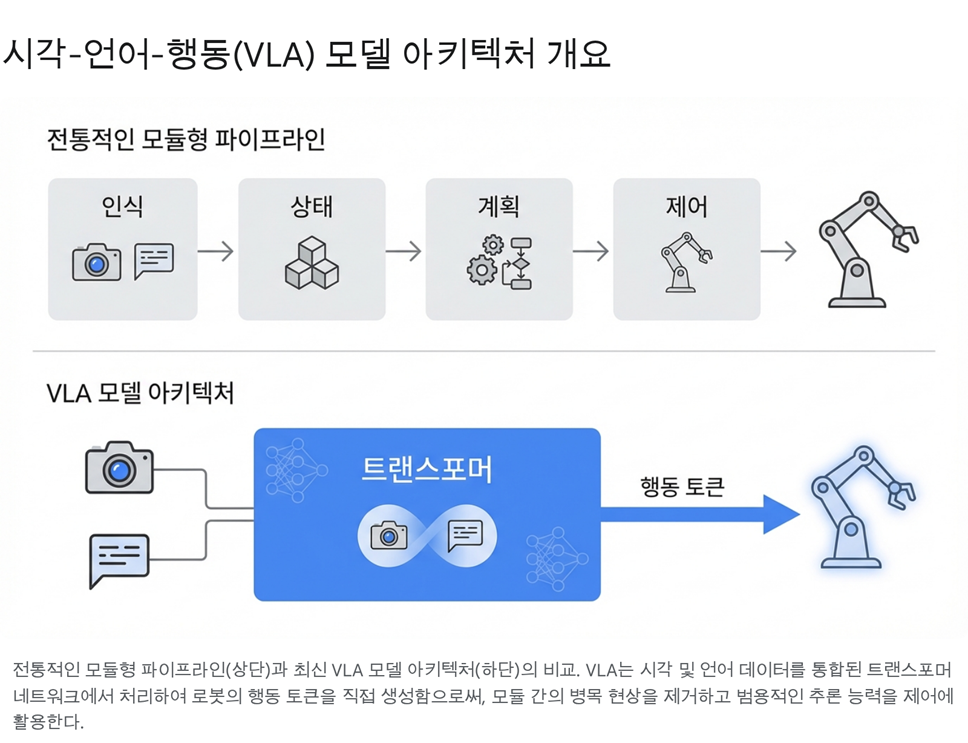
전통적인 로봇 제어 아키텍처는 감지(Sensing), 계획(Planning), 실행(Acting)이라는 세 가지 기능이 엄격하게 분리된 모듈형 파이프라인(Modular Pipeline) 구조를 취해 왔다. 각 모듈은 독립적으로 개발되고 최적화되었으나, 모듈 간의 정보 전달 과정에서 병목 현상이 발생하고, 상위 모듈의 오류가 하위 모듈로 전파되는 문제가 있었다. 또한, 각 모듈이 처리하는 데이터의 형식이 달라 정보의 손실이 불가피했다.
그러나 최신 연구 동향은 이러한 경계를 허물고 있다. 시각-언어-행동(Vision-Language-Action, VLA) 모델의 등장은 인식과 판단, 그리고 제어 신호 생성을 하나의 거대한 신경망 안에서 통합적으로 처리하는 종단간(End-to-End) 학습의 가능성을 열었다. 이는 로봇이 인간처럼 감각 입력에서 행동 출력까지를 직관적으로 연결할 수 있게 함으로써, 기존 시스템이 갖지 못한 유연성과 일반화 능력을 부여하고 있다.1

본 보고서는 이러한 기술적 대전환의 시기에 제어·로봇·시스템공학 연구자들이 주목해야 할 최신 연구 동향과 핵심 기술을 심도 있게 분석한다. 2024년과 2025년의 주요 학술 대회(ICRA, IROS, RSS, CoRL 등)와 아카이브 논문들을 바탕으로, 파운데이션 모델 기반의 로봇 지능, 3D 공간 인지의 혁신, 생성형 시뮬레이션, 그리고 산업계의 최신 상용화 사례까지 폭넓게 다룬다.
2. 파운데이션 모델과 로봇 지능의 융합
로봇 공학에서 파운데이션 모델의 도입은 단순히 기존 알고리즘의 성능을 개선하는 수준을 넘어, 로봇이 문제를 해결하는 방식 자체를 재정의하고 있다. 특히 인터넷 규모의 텍스트와 이미지 데이터로 학습된 LLM과 VLM은 로봇에게 '상식(Common Sense)'이라는 강력한 무기를 제공했다.
2.1. 시각-언어-행동(VLA) 모델: 체화된 지능의 중추
VLA 모델은 로봇 학습의 성배와도 같은 '범용성(Generalization)'을 확보하기 위한 핵심 기술로 부상했다. 기존의 로봇 학습이 특정 작업(Task-specific) 데이터셋에 의존하여 학습된 기술을 다른 환경이나 작업에 적용하기 어려웠던 반면, VLA 모델은 방대한 사전 학습 지식을 바탕으로 새로운 상황에 적응하는 제로샷(Zero-shot) 또는 퓨샷(Few-shot) 능력을 보여준다.6
2.1.1. 아키텍처의 통합과 행동 토큰화
VLA 모델의 가장 큰 특징은 입력과 출력을 토큰(Token)이라는 공통의 언어로 통일했다는 점이다. 모델은 카메라로 입력된 이미지 프레임과 사용자의 자연어 명령을 일련의 토큰 시퀀스로 변환하여 처리한다. 놀라운 점은 출력단에서도 로봇의 행동을 토큰으로 취급한다는 것이다. 로봇의 관절 각도, 엔드 이펙터의 위치 및 회전, 그리퍼의 개폐 상태 등 물리적 제어 변수들을 이산화(Discretization)하여 언어 토큰과 동일한 방식으로 생성해낸다.5
예를 들어, 구글 딥마인드(Google DeepMind)의 RT-2(Robotics Transformer 2)는 웹 데이터로 학습된 VLM의 파라미터를 기반으로 로봇 행동 데이터를 미세 조정(Fine-tuning)하여, 시각적 이해 능력과 물리적 제어 능력을 동시에 갖추게 되었다. 이는 로봇이 "식탁 위에서 쏟아진 물을 닦아줘"라는 명령을 받았을 때, '물'과 '스펀지'의 관계를 시각적으로 추론하고(Reasoning), 스펀지를 집어 물을 닦는 궤적(Action)을 생성하는 과정을 단일 신경망 내에서 수행함을 의미한다.9
최근 공개된 OpenVLA나 Pi0(Physical Intelligence 0)와 같은 모델들은 이러한 접근을 더욱 고도화하여, 다양한 로봇 하드웨어(Embodiment)에 적용 가능한 범용적인 제어 정책을 생성하고 있다. 특히 Pi0는 확산 모델(Diffusion Model)이나 플로우 매칭(Flow Matching) 기법을 도입하여, 기존의 트랜스포머 기반 모델이 가질 수 있는 행동의 불연속성을 극복하고 더욱 부드럽고 정교한 고빈도(High-frequency) 제어를 가능하게 했다.11
2.1.2. 계층적 추론 시스템: Fast vs Slow
VLA 모델의 강력한 성능에도 불구하고, 거대 모델의 연산 비용과 추론 지연(Latency)은 실시간성이 생명인 로봇 제어에 있어 극복해야 할 과제이다. 인간이 직관적인 반응(System 1)과 숙고적인 사고(System 2)를 병행하듯, 최신 로봇 제어 아키텍처 또한 이중 프로세스(Dual-process) 구조로 진화하고 있다.12
- 시스템 2 (High-level Reasoning): LLM이나 대형 VLM이 담당하며, 복잡한 장기 계획(Long-horizon planning)을 수립한다. 예를 들어 "주방을 정리해"라는 명령을 "접시를 식기세척기에 넣기", "식탁 닦기", "의자 정리하기"와 같은 하위 목표(Sub-goal)로 분해하고, 각 단계의 성공 여부를 판단한다. 이는 상대적으로 느린 주기(Low-frequency)로 작동한다.14
- 시스템 1 (Low-level Control): 실시간 센서 데이터에 반응하여 즉각적인 모터 제어를 수행한다. 경량화된 정책 네트워크나 VLA의 경량 버전이 담당하며, 수십 Hz 이상의 고빈도(High-frequency)로 작동하여 물리적 외란에 대응하고 안정적인 동작을 보장한다.
2024년과 2025년에 발표된 RoboDual, HAMSTER, DP-VLA 등의 연구가 이러한 계층적 접근을 구체화하고 있다. HAMSTER 모델의 경우, 고수준의 VLM이 거시적인 2D 이동 경로와 웨이포인트를 생성하면, 저수준의 제어 정책이 이를 가이드 삼아 세밀한 조작을 수행하는 방식을 제안했다. 또한, FiS (Fusion-in-Slot)와 같은 연구는 이 두 시스템을 별도로 두지 않고 파라미터 공유를 통해 하나의 모델 내에서 효율적으로 통합하려는 시도를 보여주었다.12 이러한 계층적 구조는 로봇이 복잡한 사고를 하면서도 기민하게 움직일 수 있는 기반이 된다.
2.2. 뉴로-심볼릭(Neuro-symbolic) 계획의 부상
LLM의 추론 능력은 뛰어나지만, 물리적 세계의 엄격한 제약 조건(Constraints)이나 인과 관계를 완벽하게 보장하지는 못한다. 소위 '환각(Hallucination)' 현상으로 인해 실행 불가능한 계획을 생성할 위험이 있다. 이를 보완하기 위해 기호적 AI(Symbolic AI)의 논리성과 신경망의 유연성을 결합한 뉴로-심볼릭(Neuro-symbolic) 계획이 주목받고 있다.15
전통적인 기호적 계획 언어인 PDDL(Planning Domain Definition Language)은 논리적으로 완벽한 계획을 수립할 수 있지만, 복잡한 환경에서는 탐색 공간이 기하급수적으로 늘어나 연산 시간이 오래 걸린다는 단점이 있다. 최근의 연구들은 LLM을 PDDL과 결합하여 이러한 문제를 해결하고 있다.
- Teriyaki 프레임워크: LLM(GPT-3 등)을 PDDL 도메인 지식으로 미세 조정하여, 기호적 플래너보다 훨씬 빠른 속도로 계획을 생성한다. 특히 전체 계획이 완성될 때까지 기다리지 않고, 생성된 행동을 즉시 실행(Action-by-action streaming)할 수 있는 구조를 제안하여 인간-로봇 협업 시의 반응성을 극대화했다. 이는 로봇이 계획을 수립하는 동안 멈춰 있는 시간을 최소화한다.15
- Flax: 신경망을 이용해 작업 수행에 필수적인 객체와 규칙의 중요도(Importance)를 예측하고, 이를 바탕으로 기호적 탐색 공간을 줄이는 '완화(Relaxation)' 기법을 사용한다. 이를 통해 대규모 물류 창고나 복잡한 미로와 같은 환경에서도 장기 계획을 빠르고 정확하게 수립할 수 있으며, 기존 방식 대비 20% 이상의 성공률 향상을 입증했다.18
이러한 연구 흐름은 로봇의 '지능'이 단순히 데이터를 학습하는 것을 넘어, 논리적 구조와 결합하여 신뢰성과 효율성을 동시에 확보하는 방향으로 나아가고 있음을 시사한다.
3. 인식의 혁명: 3D 공간 이해와 멀티모달 융합
로봇이 물리적 세계에서 유의미한 작업을 수행하기 위해서는 단순히 카메라 픽셀을 처리하는 것을 넘어, 3D 공간의 구조와 물체의 속성을 정확히 파악해야 한다. 2024-2025년의 연구는 시각적 현실감과 기하학적 정확성을 동시에 추구하는 방향으로 급격히 발전하고 있다.
3.1. 3D 가우시안 스플래팅(3D Gaussian Splatting): 로봇 시각의 새로운 표준
NeRF(Neural Radiance Fields)는 뛰어난 3D 복원 품질로 주목받았으나, 실시간 렌더링과 추론 속도의 한계로 인해 로봇의 주행(Navigation)이나 조작(Manipulation)에 직접 적용하기에는 무리가 있었다. 이에 대한 대안으로 등장한 3D 가우시안 스플래팅(3DGS)은 로봇 인식 분야의 판도를 바꾸고 있다.20
3.1.1. 명시적 표현과 실시간성
3DGS는 공간을 수많은 3D 가우시안 타원체(Gaussian Primitives)의 집합으로 표현한다. 각 타원체는 위치, 회전, 크기, 색상, 불투명도 정보를 가지며, 이를 2D 화면에 투영(Splatting)하여 이미지를 생성한다. NeRF가 신경망을 통해 픽셀마다 광선을 추적(Ray-marching)하는 암묵적(Implicit) 방식이라 연산량이 많은 반면, 3DGS는 래스터화(Rasterization) 방식을 사용하여 GPU 친화적이며 렌더링 속도가 비약적으로 빠르다.22
이러한 속도는 로봇에게 결정적인 이점을 제공한다. 로봇은 이동 중에 실시간으로 주변 환경을 3D로 복원하고 갱신할 수 있다. 또한, 가우시안 타원체라는 명시적(Explicit) 데이터 구조는 포인트 클라우드처럼 다루기 쉬워, 충돌 감지나 경로 계획 알고리즘에 직접 활용하기가 훨씬 용이하다.
3.1.2. 동적 환경과 4D 인식
정적인 환경뿐만 아니라 움직이는 물체나 사람을 인식하는 것은 로봇에게 필수적이다. 최신 연구들은 시간(Time) 차원을 추가한 4D 가우시안 스플래팅을 통해 동적 환경을 모델링하고 있다. 예를 들어, 물체를 조작할 때 물체의 변형이나 이동을 실시간으로 추적하거나, 로봇 팔과 상호작용하는 유체나 변형 가능한 물체(Deformable objects)를 모델링하는 데 3DGS가 활용되고 있다.21 NVIDIA의 연구에서는 3DGS를 물리 엔진과 결합하여 시각적 정보와 물리적 상호작용(마찰, 충돌 등)이 일치하는 고정밀 시뮬레이션 환경을 구축하는 성과를 보여주기도 했다.24
3.2. 멀티모달 융합과 고유수용감각(Proprioception)
인간이 눈으로 보면서 손끝의 감각으로 물체를 다루듯, 진정한 지능형 로봇은 시각 정보 외에도 촉각, 청각, 그리고 자신의 신체 상태를 인지하는 고유수용감각을 통합적으로 처리해야 한다.
- 촉각-시각 융합: 로봇이 물체를 파지(Grasping)할 때, 시각 정보만으로는 물체의 미끄러짐이나 강성을 파악하기 어렵다. 최근 연구들은 젤사이트(GelSight)와 같은 고해상도 촉각 센서 데이터를 시각 데이터와 함께 트랜스포머 모델에 입력하여, 더욱 섬세한 조작 기술을 학습시키고 있다.1
- 고유수용감각의 통합: 로봇 팔의 관절 각도, 속도, 토크 등의 고유수용감각 정보는 MLP(Multi-Layer Perceptron)를 통해 저차원 벡터로 인코딩된 후, VLA 모델의 시각 및 언어 임베딩과 결합된다. 이는 로봇이 자신의 신체적 한계와 현재 상태를 인지하고, 물리적으로 실행 가능한 행동을 생성하는 데 필수적이다.25 특히 Dexbotic이나 TriVLA와 같은 연구들은 이러한 이종(Heterogeneous) 데이터를 효과적으로 융합하기 위해 FiLM(Feature-wise Linear Modulation) 레이어나 전용 인코더를 설계하여 성능을 높이고 있다.25
4. 데이터와 시뮬레이션: 로봇 학습의 가속화
로봇 학습의 가장 큰 난관은 데이터의 희소성이다. 텍스트나 이미지 데이터는 인터넷에 넘쳐나지만, 로봇이 현실 세계와 상호작용하는 데이터는 수집 비용이 매우 높고 위험하다. 이를 극복하기 위해 '생성형 시뮬레이션'과 'Sim-to-Real' 기술이 비약적으로 발전하고 있다.
4.1. 생성형 시뮬레이션 (Generative Simulation)
생성형 AI 기술을 활용하여 로봇이 학습할 수 있는 가상 환경과 태스크를 무한히 생성해내는 접근법이다. RoboGen, GenSim과 같은 프레임워크는 LLM과 이미지 생성 모델을 결합하여 로봇 학습의 자동화를 실현하고 있다.26
- 자동화된 환경 생성: "설거지를 배우는 로봇"을 학습시키고 싶다면, LLM이 설거지에 필요한 단계와 물체들을 정의하고, 이미지 생성 모델과 3D 에셋 생성기가 이에 맞는 주방 환경, 그릇, 수세미 등을 가상 공간에 배치한다.
- 다양성(Diversity)의 확보: 인간이 일일이 설계하기 힘든 다양한 예외 상황(Edge cases)을 대량으로 생성할 수 있다. 예를 들어, 깨진 컵을 다루거나, 물이 넘치는 상황 등 현실에서 재현하기 힘든 시나리오를 시뮬레이션에서 미리 경험하게 함으로써 로봇의 적응력을 높인다. 연구 결과에 따르면, 이러한 생성형 시뮬레이션은 기존 방식 대비 태스크 다양성을 18.5% 이상 증가시키며, 로봇의 일반화 성능을 크게 향상시킨다.27
4.2. Sim-to-Real: 가상에서 현실로의 전이
시뮬레이션에서 학습한 정책(Policy)을 현실 세계에 적용할 때 발생하는 간극(Reality Gap)을 줄이는 것은 여전히 중요한 과제이다.
- 시각적/물리적 도메인 랜덤화: 시뮬레이션 환경의 조명, 텍스처, 카메라 노이즈뿐만 아니라 마찰계수, 물체의 질량 등 물리적 파라미터를 무작위로 변형시켜 학습함으로써, 로봇이 현실의 불확실성에 강인하게 대응하도록 한다.28
- 비전 기반 강화학습(RL)의 도약: 2025년 최신 연구들은 휴머노이드 로봇이 외부 카메라나 센서 없이, 로봇에 장착된 카메라(Egocentric vision)만을 이용하여 전신 제어(Whole-body Control)와 조작을 동시에 학습하는 성과를 보여주고 있다. Digit 로봇이 다양한 크기와 무게의 박스를 옮기는 작업을 시뮬레이션 학습만으로 현실에서 성공적으로 수행한 사례는 이 분야 기술이 성숙 단계에 진입했음을 시사한다.29 또한, 대규모 인간 모션 데이터를 휴머노이드에 맞게 리타겟팅(Retargeting)하여 학습에 활용하는 H2O와 같은 데이터셋 구축 노력도 Sim-to-Real 성능 향상에 기여하고 있다.28
5. 아키텍처 논쟁: End-to-End 대 Modular
로봇 제어 시스템을 설계하는 철학은 크게 모든 과정을 하나의 신경망으로 처리하는 End-to-End 방식과, 기능별로 모듈을 나누는 Modular 방식으로 나뉘며, 최근에는 이 둘의 장점을 취한 Hybrid 접근이 대두되고 있다.1
5.1. 접근 방식 비교
| 비교 항목 | End-to-End 아키텍처 | 모듈형 (Modular) 아키텍처 | 하이브리드 접근법 |
| 핵심 원리 | 센서 입력에서 제어 신호까지 단일 신경망으로 연결 (예: VLA) | 인식, 계획, 제어 모듈이 독립적으로 분리 및 순차 실행 | 모듈성을 유지하되, 각 모듈을 신경망으로 대체하거나 종단간 학습 요소 도입 |
| 장점 | 데이터 기반 최적화 용이, 복잡한 패턴 학습 가능, 낮은 지연 시간 잠재력 | 해석 가능성(Explainability) 높음, 디버깅 용이, 검증된 안전성 | 성능과 안전성의 균형, 유연한 시스템 설계 |
| 단점 | 막대한 학습 데이터 필요, '블랙박스' 문제로 인한 해석 난해 | 모듈 간 오차 누적, 새로운 환경에 대한 적응력 부족 | 시스템 복잡도 증가, 설계 및 튜닝의 어려움 |
| 최신 동향 | RT-X, Optimus 등 범용 로봇 제어의 주류로 부상 | 자율주행 등 안전 필수 분야에서 여전히 선호 | 신경망 플래너(System 2)와 전통적 제어기(MPC 등)의 결합 |
5.2. 트렌드 분석
최근 연구 결과에 따르면, 가정이나 비정형 제조 현장과 같이 동적이고 불확실성이 높은 환경에서는 End-to-End 방식이 선호되는 경향이 뚜렷하다. 이는 환경 변화에 대한 지속적인 적응(Continuous Adaptation)이 필요하기 때문이다.1
반면, 자율주행과 같이 수많은 안전 규제와 검증이 필요한 분야에서는 모듈형 구조를 유지하되, 각 모듈(인식, 경로 계획)의 성능을 딥러닝으로 고도화하는 방식이 주류를 이루고 있다.31 특히, LLM을 상위 레벨의 의사결정 모듈로 활용하고, 하위 레벨 제어는 기존의 제어 이론을 따르는 하이브리드 형태가 현실적인 대안으로 많이 채택되고 있다.32
6. 신뢰와 안전: 설명 가능한 로봇 AI (XAI)
로봇이 인간과 함께 생활하는 공간으로 들어오면서, 단순히 성능이 좋은 것을 넘어 '믿을 수 있는' 로봇을 만드는 것이 중요해졌다. VLA와 같은 딥러닝 모델은 내부 동작을 알기 어려운 '블랙박스'이므로, 이에 대한 안전장치(Guardrails)와 해석 가능성 연구가 활발하다.
6.1. 안전 가드레일 (Safety Guardrails)
AI가 생성한 행동이 물리적으로 안전한지 검증하는 기술이다.
- 형식 검증(Formal Verification): 로봇의 행동 계획을 LTL(Linear Temporal Logic)과 같은 수학적 논리 수식으로 변환하여, 충돌이나 금지 구역 진입과 같은 위반 사항이 없는지 증명한다. 만약 AI가 생성한 계획이 안전 수칙을 위반하면, 실행 전에 이를 차단하거나 수정한다.34
- 예측적 가드레일: 경량화된 '세계 모델(World Model)'이나 물리 엔진을 사용하여 로봇의 다음 행동 결과를 미리 시뮬레이션해본다. 예측 결과 위험이 감지되면 즉시 멈추거나 안전한 대안 경로를 생성한다. 최근에는 강화학습 기반으로 안전 제약 조건을 학습하여 VLA 모델을 정렬(Alignment)하는 연구도 진행되고 있다.35
6.2. 메커니즘 해석 가능성 (Mechanistic Interpretability)
"로봇이 왜 그런 행동을 했는가?"에 답하기 위한 연구이다. CoRL 2025 등에서 발표된 최신 연구들은 VLA 모델 내부의 트랜스포머 레이어를 분석하여, 특정 뉴런이나 벡터가 로봇의 속도, 방향, 또는 특정 물체 인식과 어떤 인과 관계가 있는지 밝혀내고 있다. 이를 통해 모델의 추론 과정에 개입하여 실시간으로 행동을 수정(Steering)하거나, 오류 원인을 파악하는 것이 가능해졌다.37 또한, CoT-VLA와 같이 로봇이 행동하기 전에 미래의 장면을 시각적으로 먼저 생성해내거나(Visual Chain-of-Thought), 텍스트로 자신의 의도를 설명하게 함으로써 투명성을 높이는 연구도 주목받고 있다.39
7. 산업계 동향 및 시장 전망
학계의 연구 성과는 테슬라, 피규어 AI, 보스턴 다이내믹스 등 선도 기업들을 통해 빠르게 상용화 단계로 진입하고 있다. 2025년은 휴머노이드 로봇이 연구실을 벗어나 실제 현장에 투입되는 원년이 될 것으로 보인다.

7.1. 테슬라 (Tesla) - 옵티머스 (Optimus)
테슬라는 자율주행(FSD) 기술을 로봇에 이식하며 가장 공격적인 행보를 보이고 있다. 옵티머스 Gen 3는 기존 모델 대비 비약적인 발전을 예고하고 있다.
- 하드웨어 혁신: Gen 3는 22 자유도(DoF)를 가진 정교한 손을 탑재하여 인간 수준의 손재주를 구현할 것으로 알려졌다. 이는 기존 Gen 2의 11 자유도에서 두 배로 늘어난 수치로, 다양한 도구 사용과 섬세한 조작이 가능해짐을 의미한다.40
- AI 및 학습: 테슬라는 별도의 코딩 없이 비디오를 보고 학습하는 '모방 학습' 능력을 강조한다. 단일 신경망이 시각 처리부터 모터 제어까지 전담하는 End-to-End 방식을 고수하며, 1.2TB의 센서 데이터를 매시간 처리하는 전용 AI 칩과 도조(Dojo) 슈퍼컴퓨터를 통해 학습 속도를 가속화하고 있다. 엘론 머스크는 이를 통해 로봇이 가사 도우미 역할을 수행할 수 있을 것이라 주장하며, 가격대를 2만~3만 달러 수준으로 낮추겠다는 목표를 제시했다.41
7.2. 피규어 AI (Figure AI) - Figure 02
오픈AI(OpenAI)와의 협력으로 강력한 언어 및 추론 능력을 탑재한 Figure 02 모델을 선보였다.
- 언어-행동 통합: 오픈AI의 멀티모달 모델을 탑재하여 사람과 자연스러운 음성 대화가 가능하고, "배가 고파"라는 말에 사과를 건네주는 식의 문맥적 추론과 행동이 가능하다. 현재 BMW 공장 등에서 실증 테스트를 진행하며 상용화 가능성을 타진하고 있다.44
7.3. 보스턴 다이내믹스 (Boston Dynamics) - Electric Atlas
오랫동안 유압식 로봇의 상징이었던 아틀라스(Atlas)를 은퇴시키고, 완전 전동식(Electric) 아틀라스를 새로 공개했다.
- 산업용 전환: 기존의 유압식 모델이 연구용에 가까웠다면, 전동식 모델은 소음이 적고 유지보수가 용이하여 실제 산업 현장 투입을 목표로 한다. 현대자동차 공장 투입을 목표로 하고 있으며, 기존의 제어 기술에 최신 AI 기반 컴퓨터 비전과 강화 학습을 접목하여 비정형 물체 조작 능력을 강화했다.46
7.4. 구글 딥마인드 (Google DeepMind)
하드웨어보다는 '로봇의 뇌'에 해당하는 파운데이션 모델 개발에 집중하고 있다.
- RT-X & Gemini Robotics: 전 세계 33개 연구소의 다양한 로봇 데이터를 통합한 Open X-Embodiment 프로젝트를 주도하며, 특정 로봇에서 배운 기술을 다른 로봇으로 전이시키는 연구를 수행 중이다. 제미나이(Gemini) 모델을 로봇 제어에 최적화하여 긴 호흡의 작업 수행 능력을 강화하고 있다.48
8. 결론 및 향후 전망
8.1. 해결해야 할 과제
비약적인 발전에도 불구하고 여전히 넘어야 할 산은 높다.
- 하드웨어와 AI의 불일치: AI 모델의 발전 속도에 비해 로봇 하드웨어(배터리, 액추에이터, 센서)의 발전은 상대적으로 더디다. 고성능 AI를 구동하기 위한 온보드(On-board) 컴퓨팅 파워와 배터리 효율성 문제가 해결되어야 한다.
- 데이터의 양과 질: 텍스트나 이미지와 달리 로봇의 물리적 행동 데이터는 여전히 부족하다. Sim-to-Real 기술과 전 세계적인 데이터 공유 이니셔티브가 더욱 중요해질 것이다.
- 안전과 윤리: 로봇이 인간의 물리적 공간을 공유함에 따라 안전성은 타협할 수 없는 가치가 되었다. 기술적 가드레일뿐만 아니라, 로봇의 오작동 시 책임 소재나 윤리적 판단 기준에 대한 사회적 합의도 필요하다.
8.2. 학문적·산업적 전망
제어·로봇·시스템공학 분야는 이제 순수 공학을 넘어 인지과학, 전산학, 데이터 과학이 융합되는 거대한 용광로가 되고 있다. 향후 연구는 단순히 제어 알고리즘을 개선하는 것을 넘어, 로봇이 어떻게 데이터를 통해 세상을 배우고 이해하는지에 대한 근본적인 질문을 탐구하는 방향으로 나아갈 것이다. 산업적으로는 2025년 이후 휴머노이드 로봇이 제조, 물류를 넘어 가정과 서비스 영역으로 확장되면서, '1인 1로봇' 시대의 초석을 다지는 시기가 될 것이다.
지금 우리는 로봇이 단순히 '움직이는 기계'에서 '생각하고 행동하는 파트너'로 진화하는 역사적인 변곡점에 서 있다. 이 보고서가 그 변화의 흐름을 이해하고 미래를 준비하는 데 있어 유의미한 통찰을 제공하기를 바란다.
참고 자료
- Multimodal perception-driven decision-making for human-robot interaction: a survey, 1월 8, 2026에 액세스, https://www.frontiersin.org/journals/robotics-and-ai/articles/10.3389/frobt.2025.1604472/full
- Large Model Empowered Embodied AI: A Survey on Decision-Making and Embodied Learning - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2508.10399v1
- From Perception to Cognition: A Survey of Vision-Language Interactive Reasoning in Multimodal Large Language Models - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2509.25373v1
- Pure Vision Language Action (VLA) Models: A Comprehensive Survey - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2509.19012v1
- Vision-language-action model - Wikipedia, 1월 8, 2026에 액세스, https://en.wikipedia.org/wiki/Vision-language-action_model
- Large Language Models for Robotics: A survey - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2311.07226v2
- Vision-Language-Action (VLA) Models: The AI Brain Behind the Next Generation of Robots & Physical AI | by RAKTIM SINGH | Nov, 2025 | Medium, 1월 8, 2026에 액세스, https://medium.com/@raktims2210/vision-language-action-vla-models-the-ai-brain-behind-the-next-generation-of-robots-physical-bced48e8ae94
- (PDF) Vision-Language-Action Models: Concepts, Progress, Applications and Challenges, 1월 8, 2026에 액세스, https://www.researchgate.net/publication/391575814_Vision-Language-Action_Models_Concepts_Progress_Applications_and_Challenges
- Stanford CS25: V3 I Low-level Embodied Intelligence w/ Foundation Models - YouTube, 1월 8, 2026에 액세스, https://www.youtube.com/watch?v=fz8wf9hN20c
- Scaling up learning across many different robot types - Google DeepMind, 1월 8, 2026에 액세스, https://deepmind.google/blog/scaling-up-learning-across-many-different-robot-types/
- From Words to Actions: The Rise of Vision-Language-Action Models in Robotics - Marvik.ai, 1월 8, 2026에 액세스, https://www.marvik.ai/blog/from-words-to-actions-the-rise-of-vision-language-action-models-in-robotics
- A Survey on Efficient Vision-Language-Action Models - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2510.24795v1
- Large language model-based task planning for service robots: A review - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2510.23357v1
- AuDeRe: Automated Strategy Decision and Realization in Robot Planning and Control via LLMs - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2504.03015v1
- A framework for neurosymbolic robot action planning using large language models, 1월 8, 2026에 액세스, https://www.frontiersin.org/journals/neurorobotics/articles/10.3389/fnbot.2024.1342786/full
- Neuro Symbolic Architectures with Artificial Intelligence for Collaborative Control and Intention Prediction - GSC Online Press, 1월 8, 2026에 액세스, https://gsconlinepress.com/journals/gscarr/sites/default/files/GSCARR-2025-0288.pdf
- A framework for neurosymbolic robot action planning using large language models - PMC, 1월 8, 2026에 액세스, https://pmc.ncbi.nlm.nih.gov/articles/PMC11184123/
- Fast Task Planning with Neuro-Symbolic Relaxation - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2507.15975v1
- [2507.15975] Fast Task Planning with Neuro-Symbolic Relaxation - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/abs/2507.15975
- 3D Gaussian Splatting in Robotics: A Survey | alphaXiv, 1월 8, 2026에 액세스, https://www.alphaxiv.org/overview/2410.12262v2
- 3D Gaussian Splatting in Robotics: A Survey - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2410.12262v2
- 3D Gaussian Splatting - Paper Explained, Training NeRFStudio - Learn OpenCV, 1월 8, 2026에 액세스, https://learnopencv.com/3d-gaussian-splatting/
- A Survey on 3D Gaussian Splatting, 1월 8, 2026에 액세스, https://www.cs.jhu.edu/~misha/ReadingSeminar/Papers/Chen24.pdf
- Building Robotic Mental Models with NVIDIA Warp and Gaussian Splatting, 1월 8, 2026에 액세스, https://developer.nvidia.com/blog/building-robotic-mental-models-with-nvidia-warp-and-gaussian-splatting/
- An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2512.11362v1
- RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2311.01455v3
- ReGen: GENERATIVE ROBOT SIMULATION VIA INVERSE DESIGN - ICLR Proceedings, 1월 8, 2026에 액세스, https://proceedings.iclr.cc/paper_files/paper/2025/file/e3b1291b7529063172d927588d2b03a1-Paper-Conference.pdf
- From Sim2Real 1.0 to 4.0 for Humanoid Whole-Body Control and Loco-Manipulation - OpenDriveLab, 1월 8, 2026에 액세스, https://opendrivelab.github.io/CVPR2025/Guangya_Shi_From_Sim2Real_1.0_to_4.0_for_Humanoid_Whole-Body_Control.pdf
- Sim-to-Real Learning for Humanoid Box Loco-Manipulation - IEEE Xplore, 1월 8, 2026에 액세스, https://ieeexplore.ieee.org/document/10610977/
- Example that illustrates the main differences among modular, end-to-end, and hybrid architectures. - ResearchGate, 1월 8, 2026에 액세스, https://www.researchgate.net/figure/Example-that-illustrates-the-main-differences-among-modular-end-to-end-and-hybrid_fig1_379273961
- A Comprehensive Literature Review on Modular Approaches to Autonomous Driving: Deep Learning for Road and Racing Scenarios - MDPI, 1월 8, 2026에 액세스, https://www.mdpi.com/2624-6511/8/3/79
- End-to-End Architecture for Real-Time IoT Analytics and Predictive Maintenance Using Stream Processing and ML Pipelines - MDPI, 1월 8, 2026에 액세스, https://www.mdpi.com/1424-8220/25/9/2945
- Autonomous driving: Modular pipeline Vs. End-to-end and LLMs | by Samer Attrah | Medium, 1월 8, 2026에 액세스, https://medium.com/@samiratra95/autonomous-driving-modular-pipeline-vs-end-to-end-and-llms-642ca7f4ef89
- Safety Guardrails for LLM-Enabled Robots - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/pdf/2503.07885v1.pdf?ref=applied-gai-in-security.ghost.io
- 10 Open Challenges Steering the Future of Vision-Language-Action Models - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2511.05936v1
- Safety Guardrails for LLM-Enabled Robots - ResearchGate, 1월 8, 2026에 액세스, https://www.researchgate.net/publication/389749056_Safety_Guardrails_for_LLM-Enabled_Robots
- Mechanistic Interpretability for Steering Vision-Language-Action Models - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/html/2509.00328v1
- [2509.00328] Mechanistic interpretability for steering vision-language-action models - arXiv, 1월 8, 2026에 액세스, https://arxiv.org/abs/2509.00328
- CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models - CVF Open Access, 1월 8, 2026에 액세스, https://openaccess.thecvf.com/content/CVPR2025/papers/Zhao_CoT-VLA_Visual_Chain-of-Thought_Reasoning_for_Vision-Language-Action_Models_CVPR_2025_paper.pdf
- Optimus (robot) - Wikipedia, 1월 8, 2026에 액세스, https://en.wikipedia.org/wiki/Optimus_(robot)
- A Complete Review Of Tesla's Optimus Robot - Brian D. Colwell, 1월 8, 2026에 액세스, https://briandcolwell.com/a-complete-review-of-teslas-optimus-robot/
- Elon Musk's Optimus Gen 3: A Technical Breakdown of the 2025 AI Revolution - Capitaly.vc, 1월 8, 2026에 액세스, https://www.capitaly.vc/blog/elon-musks-optimus-gen-3-a-technical-breakdown-of-the-2025-ai-revolution
- Tesla robot price in 2025: Everything you need to know about Optimus - Standard Bots, 1월 8, 2026에 액세스, https://standardbots.com/blog/tesla-robot
- It went viral in 2025: a new domestic robot was announced that marked a turning point in robotics, organizing objects, operating appliances, learning unprecedented tasks, and using AI to navigate unpredictable everyday environments. - Click Oil and Gas, 1월 8, 2026에 액세스, https://en.clickpetroleoegas.com.br/It-was-a-hit-in-2025-when-a-domestic-robot-was-announced-that-marked-the-robotics-field-and-organizes-objects%3A-RPC95./
- Figure AI unveils second-generation humanoid robot Figure 02 - Robotics 24/7, 1월 8, 2026에 액세스, https://www.robotics247.com/article/figure_ai_unveils_second_generation_humanoid_robot_figure_02
- Atlas | Boston Dynamics, 1월 8, 2026에 액세스, https://bostondynamics.com/products/atlas/
- Boston Dynamics Unveils New Atlas Robot to Revolutionize Industry, 1월 8, 2026에 액세스, https://bostondynamics.com/blog/boston-dynamics-unveils-new-atlas-robot-to-revolutionize-industry/
- 2025 Robotics Revolution: Latest Breakthroughs Reshaping the Industry | RoboCloud Hub, 1월 8, 2026에 액세스, https://robocloud-dashboard.vercel.app/learn/blog/robotics-2025-revolution
- General-Purpose Robot RT-X: A Collaboration between DeepMind and 33 Academic Labs, 1월 8, 2026에 액세스, https://syncedreview.com/2023/10/06/general-purpose-robot-rt-x-a-collaboration-between-deepmind-and-33-academic-labs/
'과학기술' 카테고리의 다른 글
| 재사용 무인 우주비행체 다목적 궤적설계 및 유도항법제어(GNC) 심층 기술 분석 (0) | 2026.01.13 |
|---|---|
| 항공우주 AI 무인기(UAV) 기술 리포트: 2023-2025 파운데이션 모델, 자율 비행 및 군집 제어의 진화와 미래 (0) | 2026.01.11 |
| 실시간 로봇 제어를 위한 강화학습: 현실 세계의 적용 (0) | 2026.01.09 |
| 폐루프 AI 시대로의 전환: 제어공학의 역할과 미래 (0) | 2026.01.08 |
| 비협력 우주쓰레기 포획을 위한 운용단계별 궤적최적화 및 제어 기술 연구 (0) | 2026.01.05 |



