1. 서론: 우주 엣지 컴퓨팅의 부상과 패러다임 전환
우주 탐사의 패러다임은 근본적인 전환기를 맞이하고 있다. 과거의 우주 임무가 탐사선이 수집한 데이터를 지상국으로 전송한 후, 지상의 거대 컴퓨팅 자원을 활용해 처리하고 분석하는 '다운로드 후 처리(Download-and-Process)' 방식에 의존했다면, 현재와 미래의 임무는 궤도 상에서 또는 행성 표면에서 데이터를 즉시 분석하고 의사결정을 내리는 '온보드 처리 후 실행(Process-and-Act)' 방식으로 급격히 이동하고 있다. 이러한 변화의 중심에는 인공지능(AI), 특히 딥러닝(Deep Learning) 기술이 자리 잡고 있다.

그러나 지상에서의 AI 혁명이 방대한 전력과 컴퓨팅 자원을 바탕으로 이루어진 것과 달리, 우주 환경은 극한의 제약을 부과한다. 우주선은 제한된 전력(수 와트에서 수십 와트 수준), 엄격한 발열 제어, 그리고 무엇보다도 고에너지 입자에 의한 방사선 피폭이라는 가혹한 환경에서 작동해야 한다. 이러한 제약 속에서 지상 수준의 높은 지능을 구현하기 위해서는 딥러닝 모델의 '경량화(Lightweighting)'가 필수불가결한 핵심 기술로 대두되었다.
1.1 데이터 중력(Data Gravity)과 대역폭 병목 현상
현대 우주 임무에서 생성되는 데이터의 양은 기하급수적으로 증가하고 있다. 초분광(Hyperspectral) 센서, 합성개구레이더(SAR), 고해상도 광학 카메라 등 첨단 탑재체들은 하루에 테라바이트(TB) 급의 데이터를 생성한다. 반면, 지구로 데이터를 전송하기 위한 다운링크 대역폭은 물리적 거리, 지상국 가시성, 통신 채널의 용량 한계로 인해 이러한 데이터 생성 속도를 따라가지 못하고 있다.
지구 관측 위성의 경우, 수집된 이미지의 상당수(어떤 경우에는 70% 이상)가 구름에 가려져 있어 분석 가치가 없는 경우가 많다. 이러한 '쓰레기 데이터'를 전송하기 위해 귀중한 대역폭과 전력을 소모하는 것은 비효율적일 뿐만 아니라 임무의 경제성을 저해하는 주요 요인이다. 심우주 탐사에서는 문제가 더욱 심각하다. 화성이나 목성권 탐사의 경우, 빛의 속도로도 왕복 수십 분에서 수 시간이 소요되는 통신 지연으로 인해 지상에서의 실시간 원격 제어(Teleoperation)가 불가능하다. 착륙선이 하강하는 '공포의 7분' 동안이나, 로버가 미지의 지형을 주파할 때, 탐사선은 스스로 주변 환경을 인식하고 경로를 판단해야 한다.
이러한 배경에서 '온보드 딥러닝(On-board Deep Learning, OBDL)'은 단순한 기술적 옵션이 아니라, 차세대 우주 임무의 성패를 가르는 전략적 기술이 되었다. 본 보고서는 이러한 온보드 딥러닝을 구현하기 위한 하드웨어 플랫폼의 특성, 핵심 경량화 알고리즘 기술, 그리고 우주 환경에서의 신뢰성 확보 방안을 심층적으로 분석하고, 향후 연구 개발의 방향성을 제시한다.
2. 우주 하드웨어 환경 분석: 제약 조건과 기회
성공적인 딥러닝 모델 경량화 연구를 위해서는 해당 모델이 구동될 하드웨어 플랫폼에 대한 깊은 이해가 선행되어야 한다. 우주용 프로세서는 크게 전통적인 '내방사선(Rad-Hard)' 프로세서와 최신 '상용(COTS)' 가속기로 양분된다. 이 두 진영 간의 트레이드오프를 이해하는 것이 온보드 AI 시스템 설계의 첫걸음이다.
2.1 우주 방사선 환경의 특수성
우주 공간은 지구 대기권 내와는 전혀 다른 가혹한 방사선 환경이다. 이는 반도체 소자의 물리적 손상과 논리적 오류를 유발하며, 딥러닝 가속기의 선정과 알고리즘 설계에 지대한 영향을 미친다. 주요 방사선 효과는 다음과 같이 분류된다.1
- 총 이온화 선량 (Total Ionizing Dose, TID): 긴 임무 기간 동안 누적되는 방사선 피폭량을 의미한다. 반도체 절연막에 전하가 갇히면서 문턱 전압(Threshold Voltage)의 변화를 일으키고, 누설 전류를 증가시켜 결국 소자의 영구적인 고장을 유발한다. 정지궤도(GEO)나 목성 탐사 임무 등 장기/고방사선 임무에서는 높은 TID 내성을 가진 부품이 필수적이다.
- 단일 이벤트 효과 (Single Event Effects, SEE): 고에너지 입자(양성자, 중이온 등) 하나가 소자의 민감한 영역을 통과할 때 발생하는 즉각적인 현상이다.
- 단일 이벤트 업셋 (Single Event Upset, SEU): 메모리 셀이나 레지스터의 비트 값이 반전되는 현상(0 -> 1 또는 1 -> 0)이다. 이는 물리적 손상은 없으나, 소프트웨어적으로 데이터 오염을 유발하는 '소프트 에러'이다. 딥러닝 모델에서는 가중치(Weight) 값이 변질되어 추론 정확도를 급격히 떨어뜨리는 원인이 된다.2
- 단일 이벤트 래치업 (Single Event Latch-up, SEL): 기생 티리스터(Parasitic Thyristor)가 턴온되어 과도한 전류가 흐르는 현상으로, 즉시 전원을 차단하지 않으면 소자가 영구적으로 파괴될 수 있는 '하드 에러'이다.
2.2 내방사선(Rad-Hard) 프로세서: 신뢰성과 성능의 괴리
전통적인 우주 임무에서는 방사선에 대한 내성이 검증된 Rad-Hard 프로세서를 사용해 왔다. 대표적으로 BAE Systems의 RAD750이나 최신의 RAD5545, 유럽의 LEON 시리즈 등이 있다. 이들은 특수 공정과 설계를 통해 100 krad(Si) 이상의 높은 방사선 내성을 가지며, 극한 환경에서도 높은 신뢰성을 보장한다.
그러나 이들의 치명적인 단점은 '성능'이다. RAD750과 같은 프로세서는 수백 MHz 대역에서 작동하며, 최신 상용 프로세서 대비 수십 년 뒤처진 연산 능력을 보인다.1 이는 수백만 개의 파라미터를 가진 최신 합성곱 신경망(CNN)을 실시간으로 추론하기에는 턱없이 부족한 성능이다. 따라서 복잡한 AI 알고리즘을 구동하기 위해서는 새로운 접근법이 필요해졌다.
2.3 상용(COTS) 가속기의 도입: 성능 혁명과 위험 감수
최근 뉴스페이스(New Space) 흐름과 함께, 지상의 자동차나 모바일 기기용으로 개발된 고성능 상용(COTS) 칩을 우주에 도입하려는 시도가 폭발적으로 증가하고 있다. 이들은 Rad-Hard 칩 대비 수십 배에서 수백 배 높은 전력 대 성능비(Performance-per-Watt)를 제공한다.1
2.3.1 FPGA (Field Programmable Gate Array)
FPGA는 현재 우주용 AI 가속기의 가장 현실적이고 강력한 대안으로 꼽힌다. Xilinx Zynq 7020이나 최신 Versal AI Core 시리즈는 하드웨어 로직을 재구성할 수 있어, 임무 중 알고리즘이 변경되거나 방사선으로 인한 손상 부위를 우회하도록 재프로그래밍할 수 있는 유연성을 제공한다.
- 특징: 병렬 처리에 최적화되어 있어 CNN 연산 효율이 매우 높으며, 전력 소모가 적다. 특히 방사선에 강한 내성을 가진 RT(Radiation Tolerant) 등급의 제품들이 출시되어 있어 신뢰성과 성능의 균형을 맞출 수 있다.3
- 사례: NASA의 TechEdSat, KP Labs의 Leopard DPU 등 다수의 큐브위성과 소형 위성에서 메인 AI 가속기로 채택되고 있다.5
2.3.2 VPU (Vision Processing Unit) 및 ASIC
특정 연산(주로 비전 처리나 텐서 연산)에 특화된 ASIC은 최고의 전력 효율을 제공한다.
- Intel Movidius Myriad 2/X: 유럽우주국(ESA)의 $\Phi$-sat-1(Phi-sat-1) 임무를 통해 우주에서의 효용성이 입증된 칩셋이다. 2W 미만의 초저전력으로 심층신경망 추론이 가능하여, 전력 제약이 심한 큐브위성에 이상적이다.7
- Google Coral Edge TPU: INT8 연산에 특화되어 있으며, 매우 높은 처리량(TOPS)을 자랑한다. 그러나 온칩 메모리(Cache)가 방사선에 취약하여 소프트웨어적인 보정 기법이 필수적이라는 연구 결과가 있다.2
2.3.3 임베디드 GPU
NVIDIA의 Jetson 시리즈(TX2, Xavier, Orin)는 지상 로봇 및 자율주행 분야의 표준이나 다름없는 플랫폼으로, 개발 용이성이 매우 높다(CUDA 생태계 활용).
- 특징: 강력한 연산 성능을 제공하지만, 상대적으로 높은 전력 소모(10W~60W)와 발열 문제로 인해 소형 위성보다는 중대형 위성이나 착륙선 등 충분한 전력/방열 설계를 갖춘 시스템에 적합하다.10 Planet Labs의 차세대 위성 Pelican과 Sidus Space의 LizzieSat이 이를 채택하고 있다.12
2.3.4 뉴로모픽(Neuromorphic) 프로세서
Intel Loihi나 BrainChip Akida와 같은 뉴로모픽 칩은 인간 뇌의 작동 방식을 모방하여 스파이킹 신경망(SNN)을 하드웨어적으로 구현한다.
- 잠재력: 데이터가 희소(Sparse)한 경우(예: 이벤트 기반 카메라, 변화 탐지) 극도로 낮은 전력으로 작동할 수 있어, 에너지 효율 면에서 기존 아키텍처를 압도할 잠재력을 가진다.14 NASA의 TechEdSat-13을 통해 궤도 상에서의 동작이 검증되었다.16
| 플랫폼 구분 | 대표 칩셋 | 주요 특징 | 우주 활용 사례 |
| FPGA / SoC | Xilinx Zynq 7020, Versal AI Core | 유연성, 재구성 가능, 높은 전력 효율, RT 라인업 보유 | Mars 2020, TechEdSat, KP Labs Leopard |
| VPU | Intel Movidius Myriad 2 / X | 초저전력(<2W), 비전 특화, 비행 이력 확보(Flight Heritage) | ESA $\Phi$-sat-1, Ubotica CogniSat |
| GPU | NVIDIA Jetson TX2, AGX Orin | 고성능, 개발 용이성(CUDA), 높은 전력 소모 | Planet Pelican, Sidus FeatherEdge |
| ASIC (Edge) | Google Coral Edge TPU | INT8 고효율, 높은 가성비, 방사선 민감도 이슈 | NASA SC-LEARN |
| Neuromorphic | Intel Loihi, BrainChip Akida | 스파이킹 신경망(SNN), 극초저전력, 이벤트 기반 처리 | TechEdSat-13, ISS 실험 |
3. 핵심 경량화 기술 및 알고리즘 심층 분석
하드웨어의 제약을 극복하고 고성능 AI를 온보드에서 구현하기 위해서는 모델 자체를 가볍고 빠르게 만드는 소프트웨어 기술이 필수적이다. 이를 '모델 경량화(Model Lightweighting)' 또는 '압축(Compression)' 기술이라 하며, 크게 양자화(Quantization), 가지치기(Pruning), 지식 증류(Knowledge Distillation), 신경망 아키텍처 탐색(NAS) 등으로 구분된다.
3.1 양자화 (Quantization): 온보드 추론의 표준
양자화는 신경망의 가중치(Weights)와 활성함수(Activations) 값을 표현하는 데이터의 정밀도(Bit-width)를 줄이는 기술이다. 일반적으로 딥러닝 모델은 학습 시 32비트 부동소수점(FP32)을 사용하지만, 추론 시에는 이만큼의 정밀도가 필요하지 않은 경우가 많다.
- INT8 (8-bit Integer): 현재 우주 온보드 추론의 사실상 표준(De facto Standard)이다. FP32 데이터를 INT8로 변환하면 모델 크기는 1/4로 줄어들고, 메모리 대역폭 요구량도 획기적으로 감소한다. 또한, 정수 연산은 부동소수점 연산보다 하드웨어적으로 훨씬 적은 에너지와 트랜지스터를 사용한다. Google Edge TPU와 Intel Myriad X는 하드웨어적으로 INT8 연산에 최적화되어 있다.7
- 벤치마크 결과: 초분광 이미지 분류 작업에서 FP32 모델을 INT8로 양자화했을 때, 정확도 손실은 1% 미만(무시할 수준)이었으나 처리 속도는 FPGA 상에서 2배 이상 향상되었다. 이는 대부분의 위성 영상 데이터가 가진 노이즈 특성상, 초고정밀 연산이 불필요함을 시사한다.17
- 이진화(Binary) 및 삼진화(Ternary) 신경망 (BNN/TNN): 양자화의 극단적인 형태로, 가중치를 1비트(-1, +1) 또는 2비트(-1, 0, +1)로 표현한다.
- FPGA와의 궁합: BNN은 곱셈 연산(Multiplication)을 단순한 논리 연산인 XNOR로 대체할 수 있게 해준다. FPGA는 이러한 논리 연산 처리에 매우 강력하므로, BNN을 적용할 경우 획기적인 속도 향상과 전력 절감이 가능하다. 연구 결과, 위성 이미지 분할(Segmentation) 작업에서 FPGA 기반 BNN은 GPU 기반 구현과 대등한 정확도를 보이면서도 훨씬 낮은 전력을 소모함을 입증했다.19
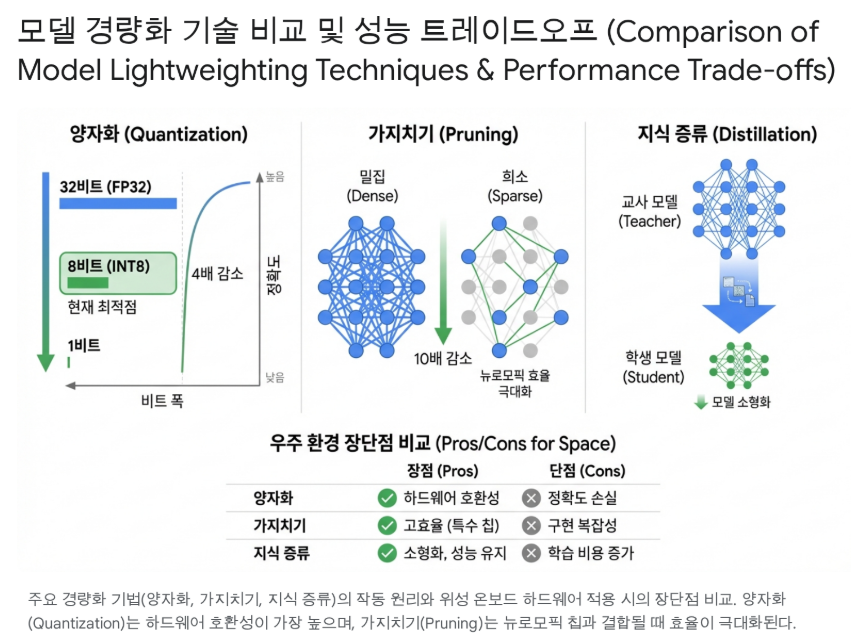
3.2 가지치기 (Pruning): 불필요한 연산의 제거
가지치기는 신경망에서 결과에 큰 영향을 미치지 않는 뉴런이나 연결(Synapse)을 제거하는 기법이다.
- 비구조적 가지치기 (Unstructured Pruning): 개별 가중치 값을 0으로 만든다. 이는 모델의 희소성(Sparsity)을 높이지만, 메모리 접근 패턴을 불규칙하게 만들어 일반적인 GPU나 CPU에서는 가속 효과를 보기 어렵다. 그러나 희소 행렬 연산을 지원하는 특수 하드웨어나 **뉴로모픽 칩(Akida 등)**에서는 극적인 성능 향상을 가져올 수 있다.14
- 구조적 가지치기 (Structured Pruning): 필터(Filter)나 채널(Channel) 전체를 제거한다. 이는 행렬 구조를 유지하므로 Movidius나 Jetson과 같은 표준 가속기에서도 즉각적인 속도 향상과 메모리 절감 효과를 얻을 수 있어 우주 임무에 더 적합한 접근법으로 평가받는다.
- 기술적 비교: 최근 벤치마크 결과에 따르면, 일반적인 압축률(4배 이하)에서는 양자화가 가지치기보다 정확도 보존 면에서 우수하지만, 초고압축이 필요하거나 하드웨어가 희소성을 지원하는 경우에는 가지치기가 유효한 전략이 된다.21
3.3 지식 증류 (Knowledge Distillation)
지식 증류는 크고 복잡한 '교사(Teacher)' 모델의 지식을 작고 가벼운 '학생(Student)' 모델에게 전수하는 학습 기법이다.
- 우주 적용 시나리오: 지상의 슈퍼컴퓨터에서 고해상도 위성 영상으로 거대 모델을 학습시킨다. 이 모델의 추론 결과를 정답(Label)으로 삼아, 위성에 탑재될 소형 모델을 학습시킨다. 이 방식은 SAR 선박 탐지 등의 임무에서 경량 모델이 교사 모델에 근접하는 정확도를 달성하면서 파라미터 수는 획기적으로 줄이는 성과를 보여주었다.23
3.4 신경망 아키텍처 탐색 (NAS) 및 경량 아키텍처
사람이 직관에 의존해 모델을 설계하는 대신, AI가 주어진 제약 조건 하에서 최적의 모델 구조를 찾아내는 NAS 기술도 주목받고 있다.
- Hardware-Aware NAS: "Zynq 7020 보드에서 50ms 안에 실행되면서 정확도가 가장 높은 모델을 찾아라"와 같이 하드웨어 제약 조건을 명시하면, 이에 최적화된 구조를 자동 탐색한다. 연구에 따르면 NAS는 방사선 오류에 더 강인한(Robust) 구조(예: 깊은 망보다는 넓은 망을 선호)를 발견하는 데에도 유효하다.24
- 경량 백본(Backbone): MobileNet, SqueezeNet, ShuffleNet과 같이 모바일 기기를 위해 설계된 효율적인 아키텍처들이 우주용 모델의 베이스라인으로 널리 사용되고 있다.
4. 온보드 딥러닝의 신뢰성 확보: 내방사선 AI 기술
지상에서는 99.9%의 정확도를 자랑하는 모델도 우주 공간에서는 무용지물이 될 수 있다. 이는 바로 방사선에 의한 소프트 에러(Soft Error) 때문이다.
4.1 소프트 에러와 딥러닝의 취약성
가중치 메모리의 특정 비트가 고에너지 입자에 의해 반전(Bit-flip)되면, 모델의 연산 결과가 완전히 달라질 수 있다. 특히 지수부(Exponent)나 최상위 비트(MSB)에 오류가 발생할 경우, 특정 뉴런의 활성값이 비정상적으로 증폭되어 전체 네트워크의 출력을 왜곡시키는 현상이 발생한다. Google Edge TPU를 대상으로 한 중성자 빔 조사 실험에서는 온칩 캐시 메모리의 오류 누적으로 인해 모델의 신뢰도가 급격히 하락하는 현상이 관측되었다.2
4.2 계층적 방어 전략
이러한 문제를 해결하기 위해 하드웨어 중복에만 의존하는 것은 과도한 비용을 초래한다. 따라서 알고리즘 수준에서의 보완이 필수적이다.
4.2.1 하드웨어 및 아키텍처 레벨: TMR
- 하드웨어 TMR (Triple Modular Redundancy): 세 개의 프로세서가 동일한 연산을 수행하고 다수결로 결과를 채택한다. 신뢰성은 높으나 전력과 무게가 3배가 되어 소형 위성에는 부적합하다.25
- 부분적 TMR: 전체 회로가 아닌, 제어 로직이나 중요 레지스터와 같은 핵심 부위에만 TMR을 적용하여 비용 효율을 높이는 방식이다.
4.2.2 소프트웨어 및 알고리즘 레벨: 알고리즘적 강인함
- 가중치 스크러빙 (Weight Scrubbing): 방사선에 강한 비휘발성 메모리(Flash 등)에 저장된 '원본' 가중치를 주기적으로 불러와 연산용 메모리(SRAM/DRAM)를 덮어씌움으로써, 누적된 비트 오류를 씻어내는(Scrub) 기법이다. 오류 발생 빈도에 따라 재로딩 주기를 조절하는 지능형 스크러빙(NR, GBR) 기법이 연구되고 있다.2
- Activation Clipping: ReLU6와 같이 활성함수의 출력값 상한을 제한하는 함수를 사용한다. 이는 비트 오류로 인해 특정 뉴런 값이 무한대로 발산하여 다음 레이어로 오류가 전파되는 것을 막아주는 '방화벽' 역할을 한다.
- Fault-Tolerant Training: 학습 과정에서 인위적으로 노이즈(비트 반전 시뮬레이션)를 주입하여, 모델이 가중치의 미세한 변화에도 둔감하게 반응하도록 훈련시키는 방법이다. 이는 별도의 하드웨어 추가 없이 모델 자체의 내성을 키우는 매우 효율적인 전략이다.27

5. 주요 응용 분야 및 최신 임무 사례 연구
실제 궤도 상에서 검증된 사례를 분석하는 것은 연구의 방향성을 설정하는 데 있어 가장 중요한 지표가 된다.
5.1 지구 관측 (Earth Observation): '스마트 필터'로서의 AI
지구 관측 위성의 핵심 목표는 데이터 감축이다.
- ESA $\Phi$-sat-1 (2020): 인텔 Movidius Myriad 2 VPU를 탑재한 최초의 AI 위성이다. CloudScout 알고리즘을 통해 초분광 이미지에서 구름을 실시간으로 분할(Segmentation)하여, 구름에 가려진 이미지를 궤도상에서 즉시 폐기했다. 이를 통해 다운링크 효율을 극대화하고 상용 AI 칩셋의 우주 활용 가능성을 증명했다.29
- 선박 및 객체 탐지: SAR 위성 등에서 선박을 탐지할 때, YOLO나 SSD와 같은 1단계(Single-stage) 탐지기가 주로 사용된다. 최근에는 '앵커 프리(Anchor-free)' 탐지기가 연산 복잡도를 낮추면서도 높은 정확도를 보여 SAR 선박 탐지의 대안으로 떠오르고 있다.23
5.2 행성 탐사 (Planetary Exploration): '자율성'의 핵심
심우주 탐사에서는 통신 지연 극복과 안전 확보가 핵심이다.
- JAXA SLIM (2024): '핀포인트 착륙(Pinpoint Landing)'을 실현한 달 착륙선이다. 하강 중 촬영한 달 표면 이미지를 내부 지도 데이터베이스와 실시간으로 매칭(Crater Matching)하여 자신의 위치를 추정했다. 이 과정에 독자적인 이미지 처리 및 경량화된 비전 알고리즘이 사용되었으며, 엔진 고장이라는 돌발 상황에서도 목표 지점 55m 이내에 착륙하는 기염을 토했다.30
- NASA Mars 2020 (Perseverance): FPGA 기반의 비전 컴퓨팅 요소(VCE)를 활용하여 지형 대조 항법(TRN)을 수행했다. 이는 착륙 중 위험한 지형(바위, 경사면)을 스스로 인식하고 피하는 기술로, 과거 수 킬로미터에 달하던 착륙 오차 범위를 수십 미터 단위로 줄였다. 또한, AutoNav 시스템은 로버가 자율적으로 경로를 계획하고 주행하는 속도를 획기적으로 높였다.1
- JAXA LUPEX (2025+ 예정): JAXA와 ISRO(인도)가 공동 개발 중인 달 극지 탐사 로버이다. 어두운 영구음영지역(PSR)에서 물을 찾기 위해, 스테레오 카메라 기반의 Visual SLAM 기술과 딥러닝 기반의 주행 가능 지형 판별 기술이 적용될 예정이다.33
5.3 우주 상황 인식 (Space Domain Awareness)
- 자세 추정 (Pose Estimation): 우주 쓰레기 제거(ADR)나 궤도상 서비스(On-orbit Servicing)를 위해, 협조하지 않는(Uncooperative) 목표 위성의 자세를 파악하는 기술이다. 합성 데이터로 학습된 CNN을 이용해 회전하는 위성의 6자유도 자세를 추정하며, 실전 적용을 위해 'Sim-to-Real' 간극을 좁히는 연구가 활발하다.35
6. 향후 연구 방향 및 해결해야 할 기술적 과제
6.1 군집 위성과 연합 학습 (Federated Learning)
스타링크와 같은 메가 컨스텔레이션(Mega-constellation) 시대가 도래함에 따라, 단일 위성의 지능을 넘어 군집 위성 간의 협업 지능이 중요해지고 있다. 우주 특화 연합 학습(Space-ified Federated Learning)은 위성들이 각자 수집한 데이터로 로컬 모델을 학습시키고, 모델의 업데이트 정보(Gradient)만을 위성 간 통신(ISL)으로 공유하여 글로벌 모델을 개선하는 기술이다. 이는 데이터 전송량을 최소화하면서도 전체 시스템의 지능을 지속적으로 진화시킬 수 있는 유망한 분야이다.36
6.2 뉴로모픽 컴퓨팅과 스파이킹 신경망 (SNN)
이벤트 기반 센서(DVS 카메라 등)와 결합된 SNN은 우주 감시 분야의 게임 체인저가 될 수 있다. 배경은 정적이고 특정 물체(우주 파편, 플레어 등)만 움직이는 우주 환경의 특성상, 변화가 있는 픽셀만 처리하는 이벤트 기반 처리는 기존 프레임 기반 처리 대비 수백 배의 전력 효율을 제공한다. Intel Loihi와 BrainChip Akida와 같은 뉴로모픽 칩의 우주 실증 연구가 이를 뒷받침하고 있다.16
6.3 해결해야 할 과제 (Technical Challenges)
- 데이터 부족 및 도메인 격차: 우주 분야는 ImageNet과 같은 표준화된 대규모 데이터셋이 부족하다. 시뮬레이션 데이터로 학습한 모델이 실제 우주의 조명, 질감, 노이즈 환경에서 성능이 저하되는 '도메인 격차(Domain Gap)' 문제는 여전히 큰 숙제이다. NASA의 AI4Mars 데이터셋 공개 등이 이루어지고 있으나, 더 다양한 임무 특화 데이터셋 구축이 시급하다.1
- 궤도상 재학습 (On-orbit Retraining): 현재 대부분의 모델은 지상에서 학습된 후 동결(Frozen)되어 탑재된다. 그러나 임무 중 센서가 노후화되거나 예기치 못한 환경 변화에 적응하기 위해서는 궤도 상에서 모델을 미세 조정(Fine-tuning)하거나 재학습하는 기술이 필요하다. 이는 제한된 연산 자원과 데이터로 수행해야 하는 난이도 높은 과제이다.38
7. JAXA 및 글로벌 로드맵 분석
글로벌 우주 기관들의 기술 개발 로드맵을 분석하면, 온보드 AI 기술의 진화 방향을 명확히 파악할 수 있다.
- 2020~2024년 (실증 및 초기 도입기): ESA의 $\Phi$-sat-1(2020)이 클라우드 탐지를 위한 AI 가속기의 궤도상 동작을 최초로 실증했다. 이어 NASA의 Mars 2020(2021)과 JAXA의 SLIM(2024)은 비전 기반의 정밀 착륙 및 항법 기술을 실제 임무의 핵심(Critical Path)으로 활용하며 '자동화(Automation)' 단계의 성숙을 알렸다.
- 2025~2027년 (고도화 및 확장기): 이 시기에는 LUPEX(2025+)와 MMX 미션이 예정되어 있다. LUPEX는 달 극지의 복잡한 조명 환경에서 자율 주행을 위한 Visual SLAM과 물 탐지 AI를, MMX는 화성 위성 포보스에서의 샘플 리턴을 위한 고도화된 자율 항법 기술을 탑재할 것이다. 이는 단순한 인식을 넘어 환경을 지도화하고 판단하는 단계로의 진입을 의미한다.33
- 2028년 이후 (인지적 자율성 및 군집 지능): 향후 로드맵은 인간의 개입을 최소화하는 완전한 자율성(Cognitive Autonomy)을 지향한다. 뉴로모픽 프로세서를 활용한 초저전력 상시 감시, 군집 위성 간의 자율 협력 및 분산 처리가 핵심 기술로 부상할 것이다. JAXA는 차세대 탐사 로드맵에서 이러한 AI 기술을 인간-로봇 협업 및 심우주 거점 구축을 위한 기반 기술로 명시하고 있다.40
8. 결론 및 제언
우주 탐사를 위한 온보드 딥러닝 모델 경량화 기술 개발은 단순히 모델의 크기를 줄이는 소프트웨어적 기교에 그치지 않는다. 이는 하드웨어(내방사선/전력 제약)와 소프트웨어(알고리즘 강인성/압축)의 정교한 공동 설계(Co-design)를 요구하는 융합 기술이다.
연구 착수를 앞두고 다음과 같은 구체적인 방향을 제언한다:
- 하드웨어 타겟의 명확화: 초기 연구 단계에서는 유연성과 성능의 균형이 잡힌 FPGA(Xilinx Zynq/Versal) 기반의 가속기를 타겟으로 선정하는 것이 유리하다. 이는 방사선 대책 수립과 알고리즘 업데이트가 용이하여 실제 위성 탑재 가능성이 가장 높다.
- 경량화 기술의 우선순위: INT8 양자화는 선택이 아닌 필수다. 이를 베이스라인으로 하되, FPGA의 특성을 극대화할 수 있는 이진화/삼진화 신경망이나 구조적 가지치기 기술을 심화 연구하는 것이 차별화 포인트가 될 것이다.
- 신뢰성 중심의 설계: 단순히 정확도(Accuracy)만을 지표로 삼지 말고, 방사선 오류에 대한 강인성(Robustness)을 핵심 성능 지표로 설정해야 한다. 학습 단계에서부터 노이즈를 주입하고, 추론 단계에서 오류를 걸러내는 알고리즘적 보호 기법을 연구의 핵심 차별점으로 삼아야 한다.
우주라는 극한의 환경은 AI 기술에 있어 가장 가혹한 시험대이자, 동시에 가장 혁신적인 발전이 일어날 수 있는 기회의 장이다. 이 연구가 미래 우주 탐사의 자율성을 여는 열쇠가 되기를 기대한다.
참고 자료
- Current AI Technology in Space, 12월 18, 2025에 액세스, https://ntrs.nasa.gov/api/citations/20240001139/downloads/Current%20Technology%20in%20Space%20v4%20Briefing.pdf
- Soft-Error Characterization and Mitigation Strategies for Edge Tensor Processing Units in Space - IEEE Xplore, 12월 18, 2025에 액세스, https://ieeexplore.ieee.org/document/10509002/
- Radiation Hardened Versal Power Tree - Renesas, 12월 18, 2025에 액세스, https://www.renesas.com/en/applications/communications-infrastructure/wireless-infrastructure/radiation-hardened-versal-power-tree
- XQR Versal™ for Space 2.0 Applications - AMD, 12월 18, 2025에 액세스, https://www.xilinx.com/content/dam/xilinx/publications/product-briefs/xilinx-xqr-versal-product-brief.pdf
- TechEdSat-13: The First Flight of a Neuromorphic Processor - NASA Technical Reports Server (NTRS), 12월 18, 2025에 액세스, https://ntrs.nasa.gov/citations/20220005780
- Leopard DPU, 12월 18, 2025에 액세스, https://catalog.orbitaltransports.com/content/brands/kplabs/SmallSat%20Catalog%20-%20Leopard%20DPU%20-%20Technical%20Data%20Sheet.pdf
- The Φ-Sat-1 Mission: The First On-Board Deep Neural Network Demonstrator for Satellite Earth Observation - IEEE Xplore, 12월 18, 2025에 액세스, https://ieeexplore.ieee.org/document/9600851/
- A First Using Artificial Intelligence in PhiSat-1 - SatNews, 12월 18, 2025에 액세스, https://news.satnews.com/2020/10/27/8134/
- Recent Radiation Test Results on COTS AI Edge Processing ASICs, 12월 18, 2025에 액세스, https://ntrs.nasa.gov/api/citations/20220009215/downloads/2022-561-Casey-Final-ETW-AI%20Chips%20v2.pdf
- Proton Evaluation of Single Event Effects in the NVIDIA GPU Orin SoM: Understanding Radiation Vulnerabilities Beyond the SoC - UPC Commons, 12월 18, 2025에 액세스, https://upcommons.upc.edu/bitstreams/ef814395-1619-43ee-ba00-6a89f0c16d83/download
- (PDF) Total Ionizing Dose Radiation Testing of NVIDIA Jetson Orin NX System on Module, 12월 18, 2025에 액세스, https://www.researchgate.net/publication/387116286_Total_Ionizing_Dose_Radiation_Testing_of_NVIDIA_Jetson_Orin_NX_System_on_Module
- Pelican | Planet Documentation, 12월 18, 2025에 액세스, https://docs.planet.com/data/imagery/pelican/
- Orlaith™ AI Ecosystem - Sidus Space, 12월 18, 2025에 액세스, https://sidusspace.com/data-solutions/artificial-intelligence/
- Akida in Space – BrainChip Space AI Solutions, 12월 18, 2025에 액세스, https://brainchip.com/akida-in-space/
- (PDF) Brainsat: Hardware Development of a Neuromorphic On-Board Computer Applied to Methane Detection from Low Earth Orbit. - ResearchGate, 12월 18, 2025에 액세스, https://www.researchgate.net/publication/386550593_Brainsat_Hardware_development_of_a_neuromorphic_on-board_computer_applied_to_methane_detection_from_low_earth_orbit
- TechEdSat-13: The First Flight of a Neuromorphic Processor, 12월 18, 2025에 액세스, https://ntrs.nasa.gov/api/citations/20220005780/downloads/CSW_TES13_AIML_Final_R5.pptx.pdf
- [2303.17951] FP8 versus INT8 for efficient deep learning inference - arXiv, 12월 18, 2025에 액세스, https://arxiv.org/abs/2303.17951
- Efficient onboard multi-task AI architecture based on self-supervised learning - arXiv, 12월 18, 2025에 액세스, https://arxiv.org/html/2408.09754v2
- Efficient FPGA Binary Neural Network Architecture for Image Super-Resolution - MDPI, 12월 18, 2025에 액세스, https://www.mdpi.com/2079-9292/13/2/266
- FP-BNN: Binarized neural network on FPGA - Department of Computing, 12월 18, 2025에 액세스, https://www.doc.ic.ac.uk/~wl/papers/17/neuro17sl0.pdf
- Pruning vs Quantization: Which is Better? - arXiv, 12월 18, 2025에 액세스, https://arxiv.org/pdf/2307.02973
- Pruning vs Quantization: Which is Better? - arXiv, 12월 18, 2025에 액세스, https://arxiv.org/html/2307.02973v1
- A Survey on Deep-Learning-Based Real-Time SAR Ship Detection - IEEE Xplore, 12월 18, 2025에 액세스, https://ieeexplore.ieee.org/iel7/4609443/4609444/10056955.pdf
- Tolerating Soft Errors in Deep Learning Accelerators with Reliable On-Chip Memory Designs - College of Engineering | Oregon State University, 12월 18, 2025에 액세스, https://web.engr.oregonstate.edu/~chenliz/publications/2018_NAS_Reliable_Accelerators.pdf
- Partial Triple Modular Redundancy: Low-Cost Resilience for FPGAs in Space Environments - DigitalCommons@USU, 12월 18, 2025에 액세스, https://digitalcommons.usu.edu/cgi/viewcontent.cgi?article=1542&context=spacegrant
- Research on Spaceborne Neural Network Accelerator and Its Fault Tolerance Design, 12월 18, 2025에 액세스, https://www.mdpi.com/2072-4292/17/1/69
- A Fault-Tolerant Neural Network Architecture | Request PDF - ResearchGate, 12월 18, 2025에 액세스, https://www.researchgate.net/publication/333336052_A_Fault-Tolerant_Neural_Network_Architecture
- A Fault-Tolerant Neural Network Architecture, 12월 18, 2025에 액세스, https://par.nsf.gov/servlets/purl/10097597/1000
- PhiSat-1 & -2 Nanosatellite Mission - eoPortal, 12월 18, 2025에 액세스, https://www.eoportal.org/satellite-missions/phisat-1
- Outcome for the Smart Lander for Investigating Moon (SLIM) 's Moon Landing - JAXA, 12월 18, 2025에 액세스, https://global.jaxa.jp/press/2024/01/20240125-1_e.html
- SLIM, Japan's precision lunar lander | The Planetary Society, 12월 18, 2025에 액세스, https://www.planetary.org/space-missions/slim-japans-precision-lunar-lander
- FPGA Mitigation Strategies for Critical Applications, 12월 18, 2025에 액세스, https://ntrs.nasa.gov/api/citations/20180007760/downloads/20180007760.pdf
- AI-Enabled Capabilities to Facilitate Next-Generation Rover Surface Operations - arXiv, 12월 18, 2025에 액세스, https://arxiv.org/html/2510.05985v1
- Visual SLAM-Based Robotic Mapping Method for Planetary Construction - PMC - NIH, 12월 18, 2025에 액세스, https://pmc.ncbi.nlm.nih.gov/articles/PMC8621460/
- A Survey on Deep Learning-Based Monocular Spacecraft Pose Estimation: Current State, Limitations and Prospects - arXiv, 12월 18, 2025에 액세스, https://arxiv.org/pdf/2305.07348
- [2511.14889] Bringing Federated Learning to Space - arXiv, 12월 18, 2025에 액세스, https://arxiv.org/abs/2511.14889
- Communication-Efficient Learning for Satellite Constellations - arXiv, 12월 18, 2025에 액세스, https://arxiv.org/html/2511.20220v1
- Autonomous Reinforcement Learning Robot Control with Intel's Loihi 2 Neuromorphic Hardware - arXiv, 12월 18, 2025에 액세스, https://arxiv.org/html/2512.03911
- The MMX Rover on Phobos: The Preliminary Design of the DLR Autonomous Navigation Experiment, 12월 18, 2025에 액세스, https://elib.dlr.de/144089/1/The_MMX_Rover_on_Phobos_The%20Preliminary_Design_of_the_DLR_Autonomous_Navigation_Experiment_Copy.pdf
- The Global Exploration Roadmap, 12월 18, 2025에 액세스, https://global.jaxa.jp/projects/sas/planetary/files/roadmap_e.pdf
- JSASS Space Vision 2050, 12월 18, 2025에 액세스, https://www.jsass.or.jp/webe/wp-content/uploads/2019/05/JSASS_SpaceVision2050_20190313.pdf
'과학기술' 카테고리의 다른 글
| 위성영상 파운데이션 모델 학습을 위한 데이터셋 생성ㆍ관리 기법 연구 (0) | 2026.01.02 |
|---|---|
| SAR 영상 기반 희소 객체 탐지를 위한 데이터셋 구축 방안 연구 (0) | 2026.01.02 |
| Liquid Neural Networks 및 Closed-form Continuous-time Neural Networks (0) | 2025.12.15 |
| Physical AI의 진화: 2023년부터 2025년까지 (0) | 2025.12.14 |
| 인체모델 기반 고공낙하 및 낙하산 시뮬레이션 알고리즘 개발 심층 연구 (0) | 2025.12.07 |



